
DFS
- 깊이 우선 탐색(Depth Frist Scan)
- 자식 노드, 자식의 자식, 자식의 자식의 자식... 계속 찾아가며 탐색하는 방식이다.
- 자식이 존재하지 않으면 자신의 부모에게 돌아가 부모가 다른 자식이 있는지 찾아보고 존재할 시 다시 탐색한다.
- 스택을 이용해 구현하면 편하다.
- A B E K L F C G D H M I J
<스택을 이용할 때의 호출 순서>
| push(A) | |
| push(B) | |
| push(E) | |
| push(K) | |
| pop() -- K | |
| push(L) | |
| pop() -- L | |
| pop() -- E | |
| push(F) | |
| pop() -- F | |
| pop() -- B | |
| push(C) | |
| push(G) | |
| pop() -- G | |
| pop() -- C | |
| push(D) | |
| push(H) | |
| push(M) | |
| pop() -- M | |
| pop() -- H | |
| push(I) | |
| pop() -- I | |
| push(J) | |
| pop() -- J | |
| pop() -- D | |
| pop() -- A |
아래는 그래프를 for문으로 탐색 할 때, 참고용으로 쓸 수 있을만한 코드를 좀 긁어왔다
[Algorithm] DFS (Depth-first Search)를 Java로 구현해보자!
안녕하세요 코딩노잼입니다. 오늘은 그래프와 트리를 탐색할 때 사용되는 DFS알고리즘에 대해서 알아보겠습니다. 1. DFS(Depth-first Search)란? DFS는 번역하면 깊이 우선 탐색이라고 합니다. 이름에서
codingnojam.tistory.com
import java.util.Stack;
public class Study_DFS_stack {
// 방문처리에 사용 할 배열선언
static boolean[] vistied = new boolean[9];
// 그림예시 그래프의 연결상태를 2차원 배열로 표현
// 인덱스가 각각의 노드번호가 될 수 있게 0번인덱스는 아무것도 없는 상태라고 생각하시면됩니다.
static int[][] graph = {{}, {2, 3, 8}, {1, 6, 8}, {1, 5}, {5, 7}, {3, 4, 7}, {2}, {4, 5}, {1, 2}};
// DFS 사용 할 스택
static Stack<Integer> stack = new Stack<>();
public static void main(String[] args) {
// 시작 노드를 스택에 넣어줍니다.
stack.push(1);
// 시작 노드 방문처리
vistied[1] = true;
// 스택이 비어있지 않으면 계속 반복
while (!stack.isEmpty()) {
// 스택에서 하나를 꺼냅니다.
int nodeIndex = stack.pop();
// 방문 노드 출력
System.out.print(nodeIndex + " -> ");
// 꺼낸 노드와 인접한 노드 찾기
for (int LinkedNode : graph[nodeIndex]) {
// 인접한 노드를 방문하지 않았을 경우에 스택에 넣고 방문처리
if (!vistied[LinkedNode]) {
stack.push(LinkedNode);
vistied[LinkedNode] = true;
}
}
}
}
}
BFS
- 너비 우선 탐색(Breadth First Scan)
- 자식1, 자식2, 자식3 ... 더 이상 찾을 자식이 없으면 자식1의 자식1, 자식2, 자식3 ... 방식으로 탐색한다.
- 큐를 이용해 구현하면 편하다.
- A B C D E F G H I J K L M
<큐를 이용할 때의 호출 순서>
| add(A) | |
| add(B) | |
| add(C) | |
| add(D) | |
| poll() -- A | |
| add(E) | |
| add(F) | |
| poll() -- B | |
| add(G) | |
| poll() -- C | |
| add(H) | |
| add(I) | |
| add(J) | |
| poll() -- D | |
| add(K) | |
| add(L) | |
| poll() -- E | |
| poll() -- F | |
| poll() -- G | |
| add(M) | |
| poll() -- H | |
| poll() -- I | |
| poll() -- J | |
| poll() -- K | |
| poll() -- L | |
| poll() - M |
위와 같은 분의 코드를 또 긁어왔다. 참고용.
[Algorithm] BFS(Breadth-first search)를 Java로 구현해보자!
안녕하세요 코딩노잼입니다. 오늘은 BFS(너비 우선 탐색)을 Java로 구현해보겠습니다. 1. BFS(Breadth-first Search) BFS는 너비 우선 탐색이라고 부르기도 하며, 코딩 테스트에서 자주 등장하는 알고리즘
codingnojam.tistory.com
import java.util.LinkedList;
import java.util.Queue;
public class StudyBFS {
public static void main(String[] args) {
// 그래프를 2차원 배열로 표현해줍니다.
// 배열의 인덱스를 노드와 매칭시켜서 사용하기 위해 인덱스 0은 아무것도 저장하지 않습니다.
// 1번인덱스는 1번노드를 뜻하고 노드의 배열의 값은 연결된 노드들입니다.
int[][] graph = {{}, {2, 3, 8}, {1, 6, 8}, {1, 5}, {5, 7}, {3, 4, 7}, {2}, {4, 5}, {1, 2}};
// 방문처리를 위한 boolean배열 선언
boolean[] visited = new boolean[9];
System.out.println(bfs(1, graph, visited));
//출력 내용 : 1 -> 2 -> 3 -> 8 -> 6 -> 5 -> 4 -> 7 ->
}
static String bfs(int start, int[][] graph, boolean[] visited) {
// 탐색 순서를 출력하기 위한 용도
StringBuilder sb = new StringBuilder();
// BFS에 사용할 큐를 생성해줍니다.
Queue<Integer> q = new LinkedList<Integer>();
// 큐에 BFS를 시작 할 노드 번호를 넣어줍니다.
q.offer(start);
// 시작노드 방문처리
visited[start] = true;
// 큐가 빌 때까지 반복
while (!q.isEmpty()) {
int nodeIndex = q.poll();
sb.append(nodeIndex + " -> ");
//큐에서 꺼낸 노드와 연결된 노드들 체크
for (int i = 0; i < graph[nodeIndex].length; i++) {
int temp = graph[nodeIndex][i];
// 방문하지 않았으면 방문처리 후 큐에 넣기
if (!visited[temp]) {
visited[temp] = true;
q.offer(temp);
}
}
}
// 탐색순서 리턴
return sb.toString();
}
}
동적 계획법(Dynamic Programming)
- 재귀 과정에서 이전에 호출했던 함수의 결과값을 기억해 재사용시 재귀 호출의 불필요한 반복을 줄이는 방법이다.
ex) 피보나치 수열(1, 1, 2, 3, 5) 5를 재귀함수로 풀었을 때의 로직
fib(5) = fib(4) + fib(3)
fib(4) = fib(3) + fib(2)
fib(3) = fib(2) + fib(1)
fib(2) = 1
fib(1) = 1
이 구조를 트리로 풀어보자면,
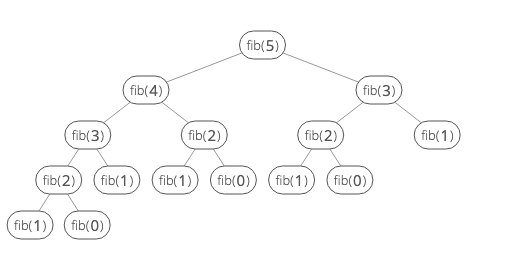
다음과 같이, fib(3), fib(2)의 빈번한 호출이 발생한다는 것이다. 이럴 때, fib(3), fib(2), fib(1)의 결과값을 미리 알고 있는 변수가 있다면? 속도가 크게 줄어들 것이다.
위 트리로 예를 들자면, fib(5)를 처음 실행할 땐 결과를 알 수 없는 fib(4), fib(3), fib(2), fib(1), fib(0)의 결과값을 미리 저장해놓으면, fib(4)의 우측 자식 노드인 fib(2)의 결과값은 이미 알고 있기때문에
fib(3)을 실행할 때용된 작업 수 + 결과값을 알고있는지 스캔하는 작업수
로 간소화 시킬 수 있는 것이다. fib(5) 역시 우측 자식 노드인 fib(3)의 결과값을 이미 알고있기때문에 위와 같은 방식으로 작업수가 크게 줄어들게 된다. 이게 동적 계획법이다.
코드는.. 언젠가 써봐야지..... 시간 남을때.....
'내가 배운 것들 > 알고리즘' 카테고리의 다른 글
| 항해99 11/13(토) 알고리즘 (0) | 2021.11.13 |
|---|---|
| 항해99 11/12(금) 알고리즘 - 알아서 푼 것들 (0) | 2021.11.12 |
| 항해99 11/11(목) 알고리즘 (0) | 2021.11.11 |
| 항해99 11/11(목) 알고리즘 - 알아서 푼 것들 (0) | 2021.11.11 |
| 항해99 11/10(수) 알고리즘 - 알아서 푼 것들 (0) | 2021.11.10 |

댓글